如何利用 MapReduce 查询项目下所有实例的标签?
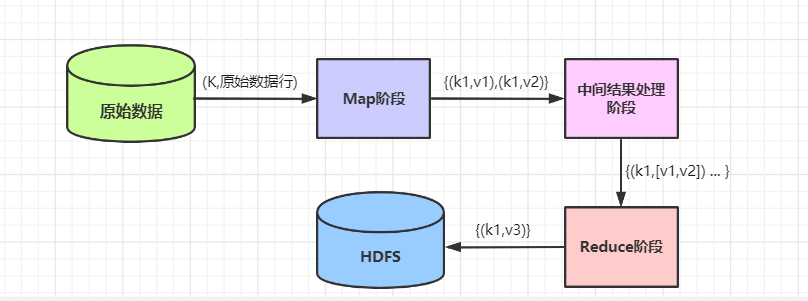
在大数据处理中,MapReduce 是一种强大的编程模型,它用于处理大规模数据集。对于需要查询项目下所有实例标签的场景,MapReduce 提供了高效的解决方案。

一、理解 MapReduce 模型
MapReduce 模型分为两个主要阶段:Map 阶段和 Reduce 阶段。Map 阶段负责数据的分解和初步处理,Reduce 阶段则负责数据的汇总和输出。通过这两个阶段的处理,我们可以实现对大规模数据的分析和查询。
二、应用 MapReduce 查询项目下所有实例的标签
-
数据准备:首先,我们需要将项目下的所有实例标签数据存储在 Hadoop 文件系统中。这些数据可以是文本文件、CSV 文件或其他格式的文件。
-
编写 Map 函数:Map 函数的目的是将输入的数据分解成键值对的形式。在这个场景中,我们可以将每个实例的标签作为键,实例的其他信息作为值。例如,一个 Map 函数可能将每个标签与其对应的实例 ID 相关联。
-
Map 阶段处理:在 Map 阶段,每个 Map 任务会读取一部分数据,并应用 Map 函数。每个 Map 任务会输出一系列的键值对,这些键值对表示了每个标签与其实例的对应关系。
-
Shuffle 和 Sort 阶段:MapReduce 框架会自动进行数据的 Shuffle 和 Sort 操作。这个阶段会将具有相同键的值聚集在一起,为 Reduce 阶段做准备。
-
编写 Reduce 函数:Reduce 函数的目的是对具有相同键的值进行汇总或处理。在这个场景中,Reduce 函数可能用于统计每个标签的出现次数或用于其他形式的汇总操作。
-
Reduce 阶段处理:Reduce 阶段会读取 Shuffle 和 Sort 阶段输出的数据,并应用 Reduce 函数。这个阶段会输出最终的查询结果,即项目下所有实例的标签及其统计信息。
三、结果输出与使用
最后,MapReduce 框架会将查询结果输出到 Hadoop 文件系统中或其他指定的存储位置。用户可以通过编程或使用 Hadoop 的命令行工具来访问和查看这些结果。这些结果可以用于进一步的数据分析、决策制定或其他用途。
通过以上步骤,我们可以利用 MapReduce 查询项目下所有实例的标签,并获得高效的查询结果。这种方法适用于处理大规模的数据集,并提供了灵活的编程模型来满足各种查询和分析需求。


























